
Welcome to the 2,739 new readers this week! The nocode.ai newsletter now has 13,152 subscribers.
Remember the AI Bootcamp is NOW AVAILABLE and FREE for everyone. 7,000+ AI enthusiasts are already in.
Data is the cornerstone that empowers algorithms to learn, evolve, and deliver precise results.
Among various terminologies, a 'Data Pile' has emerged as a significant concept that is fundamental in the training of Language Models (LLMs) and other AI models.
Here's what I'll cover today:
- What is a Data Pile?
- Key principles of a Data Pile
- How to Create a Data Pile
- Examples of Data Piles
- The IBM Data Pile to train Enterprise LLMs
Let's do this! 💪
What is a Data Pile?
LLMs are a type of AI that uses deep learning techniques to understand, summarize, generate, and predict new content. They are trained on massive datasets of text and code, which allows them to learn the patterns and relationships between words and phrases. This knowledge can then be used to perform a variety of tasks, such as generating text, translating languages, writing different kinds of creative content, and answering your questions in an informative way.
The richer and more diverse the data, the better the training, leading to AI models with enhanced performance and precision.
A Data Pile is essentially a massive, structured collection of data that serves as the training ground for AI and ML models, especially LLMs.
Data piles include text from a variety of sources, such as books, articles, code, and social media posts in different domains, such as science, technology, business, and the arts. This diversity of data helps LLMs to learn to generate and understand text that is relevant to a wide range of topics.
Key principles of a Data Pile
In AI, it is all about the quality of the data. The key principles of effective data piles are:
- Volume - They contain massive amounts of data, from hundreds of thousands to billions of examples. This fuels robust training.
- Diversity - They include varied formats like text, tables, images, and video. Different data types enable multi-modal training.
- Relevance - The examples directly relate to the domain the AI needs to master, whether it's customer support or legal contracts.
- Structure - Meticulous organization and tagging make the data easily accessible to training algorithms.
- Benchmarking - Subsets allow evaluation of model performance during and after training.
Scale and quality ultimately determine the capabilities of trained models. A "garbage in, garbage out" scenario can occur with poorly managed data.
How to Create a Data Pile
Creating a data pile can be a complex and time-consuming task. Here are some required steps:
- Identify your needs. What kind of AI models do you want to train? What kind of tasks do you want them to be able to perform? Once you know what you need, you can start to identify the types of data you need to collect.
- Find data sources. There are a variety of sources of data that you can use to create a data pile. Some common sources include:
- Publicly available datasets, such as the Pile and the Common Crawl
- Your own company's data, such as customer records, product data, and employee data
- Data from third-party providers, such as social media platforms and e-commerce websites
- Clean and process the data. Once you have collected your data, you will need to clean and process it to make it suitable for training your AI models. This may involve removing noise and errors, converting the data into a consistent format, and balancing the dataset to ensure that it contains a representative sample of all the different types of data you want your AI models to be able to handle.
- Store and manage the data. Once your data is clean and processed, you will need to store it in a way that is secure and accessible. You will also need to develop a system for managing the data and keeping it up to date.
While not every AI consumer needs to build data piles from scratch, companies looking to train and optimize custom LLMs will require robust data repositories tailored to their goals. Curating domain-specific data piles is the fuel-accelerating capability.
Examples of Data Piles
Here are a few examples of data piles that have been used to train LLMs and other AI models:
- The Pile is a 825 GB diverse, open-source language modeling data set that consists of 22 smaller, high-quality datasets combined together.
- The Common Crawl is a massive dataset of web pages that is updated regularly. It can be used to train LLMs to understand and generate text that is relevant to the real world.
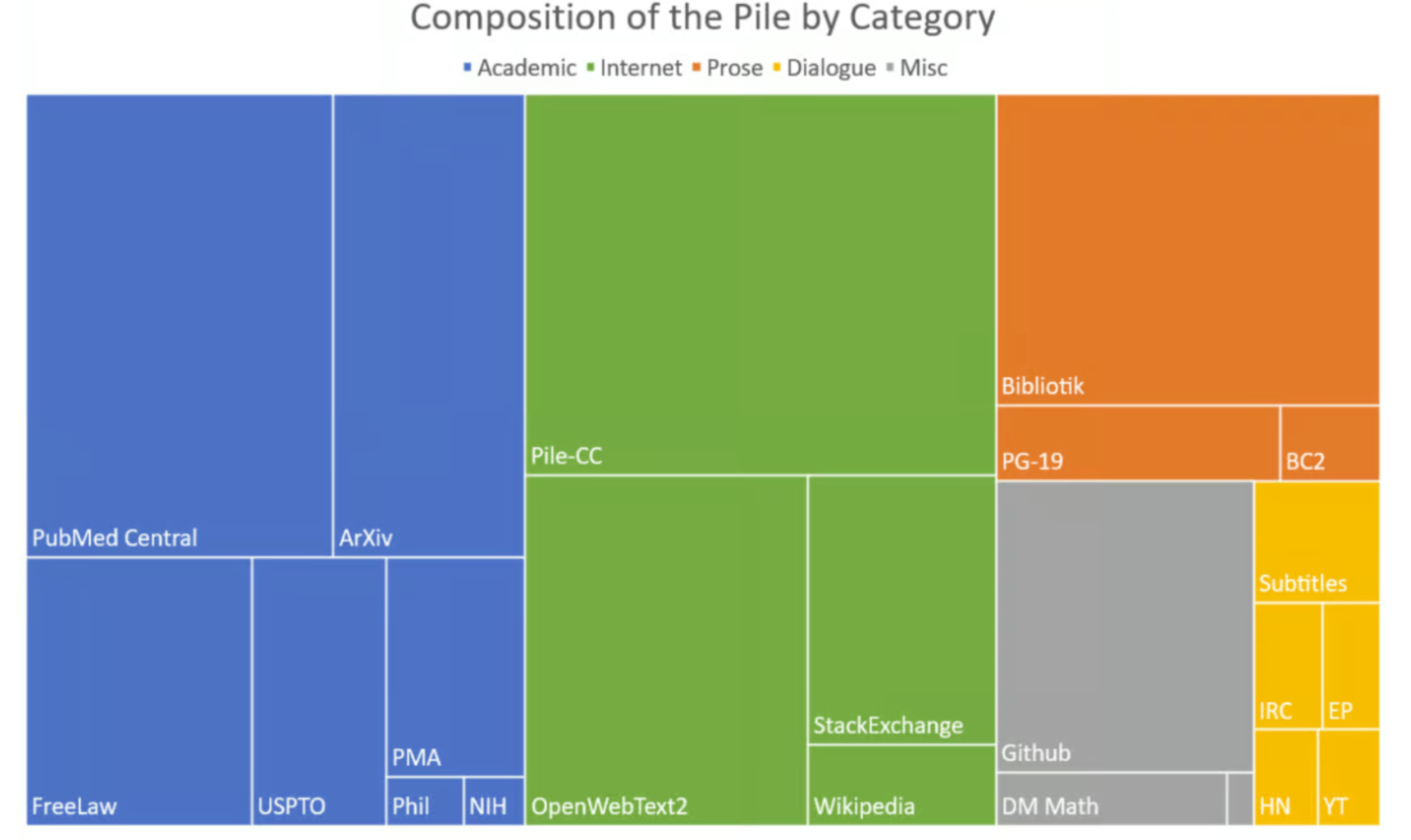
The IBM Data Pile to train Enterprise LLMs
IBM recently announced the Granite Model series, which is a collection of generative AI models designed to help businesses build and scale generative AI.
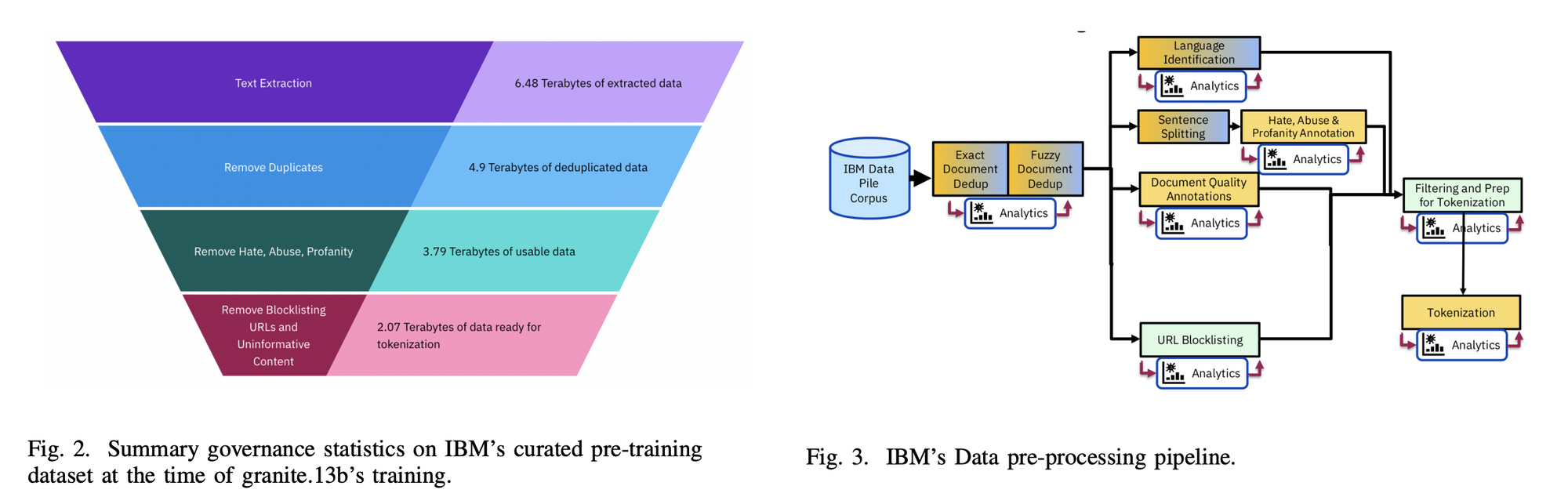
During the pre-training of granite.13b, IBM curated 6.48 TB of data, which was reduced to 2.07 TB after pre-processing. The datasets consisted of filtered English text and code within unstructured data files, with all non-text elements like images and HTML tags removed. For training granite.13b, 1 trillion tokens were generated from 14 different datasets.

The governance process is structured into three phases: data clearance and acquisition, pre-processing, and tokenization, each with focused sub-processes to address various governance aspects. Before any data is integrated into IBM's pre-training dataset, it undergoes a thorough review during the data clearance process to evaluate technical, business, and governance aspects, ensuring a meticulous approach toward data management and compliance with evolving best practices and regulatory requirements in AI model development.
From data request to tokenization, aiming to create an auditable trail from the trained model back to the specific dataset version used, including details on each pre-processing step.
Closing remarks
Data piles are essential for training LLMs and other AI models. By creating a data pile that is tailored to your specific needs, you can train AI models that can be used to improve a variety of business processes and applications.
A Data Pile is a vital asset that propels the capabilities of AI and LLMs to new heights. By understanding and implementing a structured approach to building a Data Pile, business professionals can significantly contribute to advancing AI and ensuring its readiness for tackling real-world challenges.
Join the AI Bootcamp! 🤖
Join 🧠 The AI Bootcamp. It is FREE! Go from Zero to Hero and Learn the Fundamentals of AI. This Course is perfect for beginner to intermediate-level professionals who want to break into AI. Transform your skillset and accelerate your career. Learn more about it here:
Cheers!
Armand 😎